アミフィアブルは、Webアプリの自動テストにおける大規模言語モデル(LLM)を活用したSeleniumベースのWebブラウザ自動操作によるテストフレームワークについて、新たに論文を発表しました。
本論文は、2025年11月にベトナムで開催された知識工学とシステム工学分野の国際会議「KSE2025」にて発表されたものです。
LLMを用いて高品質なテストケースを自動生成する新たな手法を構築し、既存の指標評価を大幅に上回る性能を示しています。
アミフィアブル「Webアプリ自動テストにおけるLLM活用論文」
発表媒体:KSE2025 (Knowledge and Systems Engineering)
発表日:2025年11月6日~11月8日
論文タイトル:Finetuning LLMs for Automatic Form Interaction on Web-Browser in Selenium Testing Framework
著者:北陸先端科学技術大学院大学 グエン・ミン研究室 アミフィアブルAI研究部(Nguyen-Khang Le、Hiep Nguyen、Ngoc-Minh Nguyen、Son T. Luu、Trung Vo、Quan Minh Bui、野村尚新、Le-Minh Nguyen)
現代のWebアプリ開発において不可欠なSelenium等の自動操作フレームワークですが、テスト用スクリプトの手動作成には多大な手間と時間がかかるという課題がありました。
また、LLMによるコード生成も期待されていましたが、「構文的に正しい」「実行可能」「入力フィールドの意図に適合」という条件を全て満たすスクリプトを自動生成することは容易ではありませんでした。
本研究はこれらのギャップを埋めるため、LLMが高品質なSeleniumテストケースを自動生成できるよう訓練する新しい手法の構築を目的としています。
研究のポイントと成果
本研究では、Webブラウザ自動操作に対し、既存にない体系的なアプローチを提示しています。
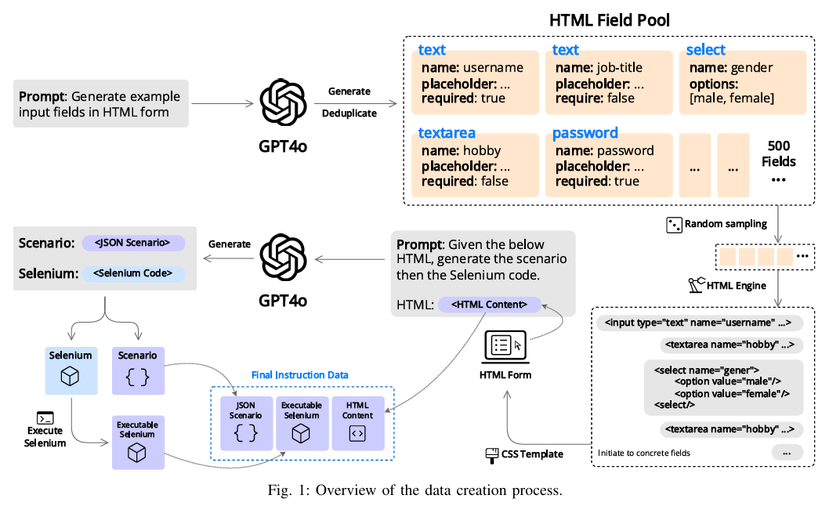
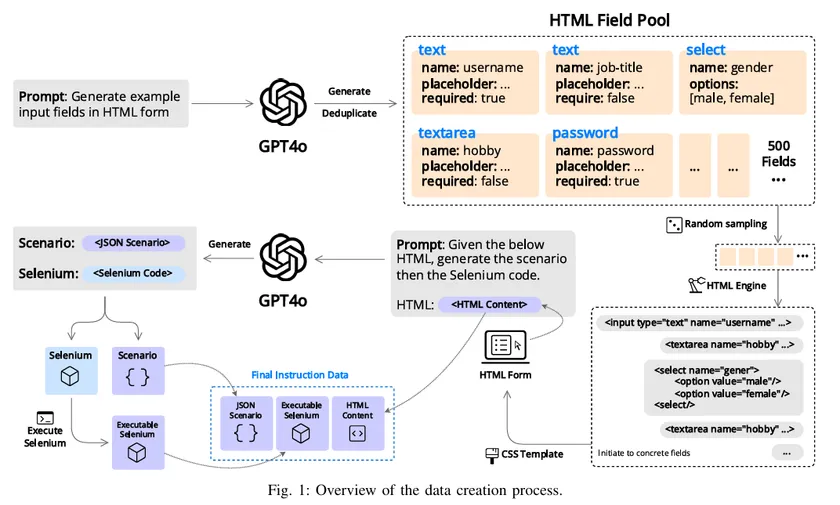
まず、多様な実世界のウェブフォームを対象とした、初の「Webブラウザ自動操作テスト用専用データセット」を構築・公開しました。
さらに、GPT-4oを中心に設計したデータ生成パイプラインにより、生成されたコードを実際に実行し、失敗したものを削除するフィルタリング戦略を採用しています。
これにより、「実行可能である」サンプルのみを残す仕組みを確立しました。
この手法によりチューニングしたLLM(Qwen2.5、Qwen3、Llama3.1等)は、GPT-4oを含む強力な商用LLMと比較しても優れた性能を発揮しました。
構文の正確さ、実行可能性、入力フィールドカバレッジのすべての評価指標において、従来よりも10%ほど向上するという結果が得られています。
今後の展望
本研究で構築されたベンチマーク、データセット、方法論は、「フォーム中心のWeb自動化」に取り組むための重要な基盤となります。
今後はLLMベースのWebブラウザ操作自動化の応用研究を促進し、ソフトウェアテストが完全自動化するための基礎となることが期待されます。
アミフィアブルによる「Webアプリ自動テストにおけるLLM活用論文」の紹介でした。